
Platform Engineering vs. Site Reliability Engineering
Striker and goalie. Offense and defense. Deploy and recalibrate. Many disciplines have dichotomy between the tasks that accomplish a goal and tasks that protect the ability to do so. Delivering features, building out user flows, and optimizing conversion rates constitute the "offense" of many software companies. All of these activities are directly tied to the goal of growing the business. Defensive tasks encompass security, operations, and disaster recovery. These tasks are designed to prevent loss and empower the offense.
An engineering team cannot run optimal code or move the business forward with a weak infrastructure.
In the software world, this alliance is realized through the engineering and operations teams. Some organizations refer to these as the "profit-center" and "cost-center," respectively.
Traditional site reliability engineering
Though symbiotic, the relationship between engineering and operations may encounter pitfalls at more complex organizations. The introduction to Google's Site Reliability Engineering: How Google Runs Production Systems describes how the two groups may have varied goals, backgrounds, skill sets, incentives, vocabulary, and assumptions. And when left unchecked, strife can form as organizational effectiveness breaks down.
Google's solution to this problem is the discipline of site reliability engineering (SRE). Developers are tasked with writing software that creates a stable environment for the deployment and operation of the infrastructure. Site reliability engineers at Google work with development teams on a sort of contract — SRE runs the application only if development follows the practices needed to make the application run efficiently. If the development team does not hold up their end of the bargain, then the SRE will decline to hold up theirs and work with teams who do.
This works well for Google, but turning down work from one part of our engineering team is not an option for the Aha! team. We have no site reliability engineers on staff at Aha! — because we found a better way.
Unified engineering goals
We solved the problem of the development-operations split by defining clear goals for our dedicated platform team. Our platform team has goals similar to a traditional operations team, such as:
- Operability — How do we run the system on a day-to-day basis and make routine changes?
- Reliability — How do we ensure the system is available for our customers?
- Resilience — When the system is unavailable, how do we get it running again?
- Observability — How do we ensure that we know before our customers when the system needs help?
We have also adopted six additional goals to help us create a happy, effective, and high-performing engineering team:
Inverse toil
Toil refers to the time engineers spend doing repetitive work that doesn't deliver real value to customers. While the amount of manual work the platform team needs to do to operate production is higher than the rest of the engineering team, we still try to keep our time spent toiling to a minimum. For most of our platform engineers, it's less than 20% of their time. Google's SREs target 50% or less time spent toiling, so we believe that our investments in automation have been very effective.
Release velocity
How long does it take a pull request to be deployed after being flagged as ready? While we attempt to optimize the time taken in continuous integration, test automation is not a core focus for us. Our developers closest to the code are best suited to test it, so we leave that responsibility to them. We instead focus on the deployment pipeline — building the core images and getting them into production. Simplifying that process allows it to be done many times a day.
Change management
In addition to deployment speed, some changes require a gradual rollout or an experimental stage to validate the changes we made. The platform team manages the feature flag functionality at Aha! and continues to extend it to provide support for more use cases.
Developer productivity
The platform team maintains a robust logging system to allow our engineers to troubleshoot problems in production quickly and effectively without direct access to customer data. We maintain the Docker setup for local development to give engineers a stable way to run the application and all of its dependencies. Our dynamic staging setup allows us to get new features in front of the product, marketing, and Customer Success teams early in the development process.
Application performance
All engineers should attempt to create a performant application. Our focus on monitoring and observability allows us to find problems in production and start the troubleshooting process. Some features may need to go back into development for optimization, but we can often solve the problem through algorithmic tweaks, indexing changes, or other database management techniques. Our experience looking into these issues gives us a sense of where additional caching, reducing object allocations, or other techniques could be used to bolster end-user performance.
These goals and techniques are also shared by the DevOps movement, which attempts to push all the operations work back onto the engineering team. However, developing a large monolithic Rails application with a robust and modern front-end framework encompasses two very deep skill sets. Asking all of our engineers to also be AWS, networking, and database engineers is asking far too much.
Our platform team serves and empowers the rest of the engineering organization. All of our goals unite to serve the company vision.
Making complicated problems simple
Without new features to uncover what is currently possible with our infrastructure, we wouldn't be able to solve complex problems. Part of that empowerment entails building out all-new infrastructure and paradigms that can be used to solve tomorrow's problems. We've made a massive effort toward integrating Kafka into our infrastructure this year, which is typical of this kind of investment. By having some space away from product-facing work, we're able to think of our product engineers as internal customers. We can build out tools and infrastructure that will support the development of future features and products.
Platform for profit
Remember the profit-center vs. cost-center distinction? New development generally gets billed as profit-generating, but the operations side of an organization has the unique ability to drive costs down. This is done through fine-tuning the spend on Cloud resources, optimizing execution to require less of those resources in the first place, and selecting time-saving technologies.
Infrastructure budget is a vital component of the technical roadmap for any platform team. When the development team is bottlenecked for infrastructure reasons, the organization loses out on critical first-mover advantages in the marketplace.
Poor engineering practices can lead to a deficit of our most important asset — the team.
We want our teammates to love what they do — increasing employee joy is the aim and core of our company's existence. And it makes financial sense too. Replacing an engineer's institutional knowledge and expertise takes time. Attrition makes your hiring plan doubly difficult to achieve.
Need for speed
Focusing on optimization allows platform engineers to improve the company's service in noticeable ways. Speed is a feature because performance expectations are similar to the delays we expect in a normal conversation. A response of 100ms feels instantaneous but delays longer than one second start to interrupt the user's flow of thought. Beyond four seconds, the user can no longer smoothly interact with a system.
Products in your daily workflow should be reliable and resilient — these two factors drive the happy use of software.
Failures can occur through human error, hardware malfunction, or bugs in vendor packages. However, my experience has shown that a system that recovers quickly when it fails is viewed more favorably than one that fails infrequently but has a longer recovery time.
A system in this case may refer not only to your software and hardware, but also your operations, engineers, and customer success teams. When failures are still within the realm of exceptional behavior and are fixed rapidly, we find those customer interactions are generally positive — even lovable. Customers who love your product will keep using it (reducing churn, increasing profit) and expand the use of the product within their own organization. Platform teams support the broader engineering organization by being prepared to respond quickly to the most debilitating failure modes. This is a core overlap with SRE teams as well.
Structuring engineering teams
If SRE teams are the defense and engineers are the offense, then platform teams are the mid-fielders. They save goals as often as they score them. Their presence makes the rest of the engineering organization more effective at their core objectives.
However, keep in mind the time spent toiling. If the platform, infrastructure, QA, and tooling engineers spend over half of their time responding directly to incidents or on-call work, you may need a dedicated reliability team.
If every week has a new emergent behavior that requires platform engineers to drop everything and fix it, it's time to adopt more proactive measures to build resilience, monitoring, and fault-tolerance. And when those tasks take up more than half the platform team's time, it's time to honor reality and break off a dedicated reliability engineering team.
Platform and SRE teams do much of the same work — the division between them is more like a gradient than a clear line:
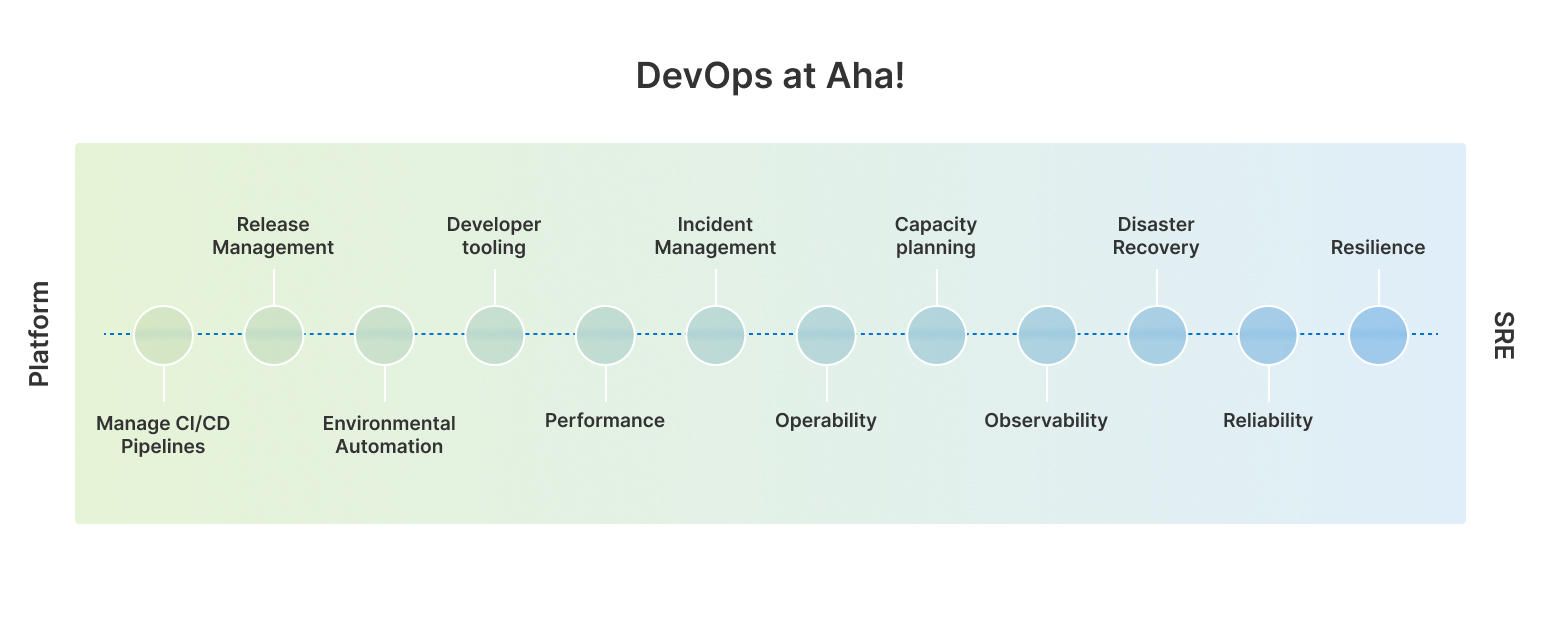
When the platform team is fully aligned with engineering and company goals, it can incorporate a healthy SRE culture that meets its needs. Focusing on observability, recovery, and reliability saves costs and increases reliability while the platform team works on enhancing the developer experience and building new infrastructure for future features or projects.
Grow your career and be happy
If this kind of alignment and environment sounds intriguing to you, come join us and work with the sharpest engineers I've ever had the pleasure of calling colleagues. Career happiness comes from doing meaningful work with motivated teammates and being appreciated for it. That is Aha! — a talented group of people changing how the best-known companies innovate and bring products to market.


