Partitioning a large table in PostgreSQL with Rails
Keeping a reliable history of changes is essential for our users. They need to know when a record was updated, who made the change, and why. They could be anxiously awaiting a notification about a dependency that is blocking their work. Maybe they want to understand why a report looks different from the last time they saw it. Or perhaps they accidentally deleted something and want to restore it.
Our auditing system makes this possible. It started as a heavily customized fork of the audited gem, using Active Record callbacks to track changes. Each time a record is created, updated, or deleted, we insert a new row into the audits table in Postgres within the same transaction as the change being tracked.
Over time, the audits table grew. And grew. By mid-2024, it held more than a decade of history — large enough to start causing real problems. In this post, we'll walk through how we partitioned our largest Postgres table using Rails, including the migration strategy, technical trade-offs, and lessons learned along the way.
Big tables have big drawbacks
How large is too large?
Our system contained billions of audits rows, consuming terabytes of storage — nearly half of our database.
At this scale, we ran into several significant challenges:
- Rising costs: Our monthly Amazon RDS storage and backup costs were five figures.
- Operational risk: Disaster recovery became more complex. In scenarios where we couldn't rely on RDS snapshots, backups and restores took hours.
- Degraded query performance: Large tables slow down queries due to …
- Index size: As indexes grew too large to fit in memory, queries relied more on disk I/O, increasing latency.
- Inefficient scans: Sequential scans took significantly longer, and even indexed lookups had to touch more disk blocks as the table grew.
Hot-to-cold access pattern
The audits table follows a hot-to-cold access pattern with high temporal locality. Most reads and all writes occur within the first hour after insertion. To quantify this, we instrumented our application to track the age of the oldest audit fetched per query, reporting it as a custom metric in Datadog. This data showed that over 90% of queries target rows inserted in the last 30 days, after which access drops sharply.
To handle this pattern efficiently, we built the audits archiver: an ETL process that migrates audits older than 12 months to Amazon S3, where storage is cheap, durable, and infinitely scalable. Each month's archival process includes detailed reconciliation to ensure the data in S3 matches Postgres before the archived rows are removed from the database. Historical audits are still accessible in cold storage while keeping the database lean and performant.
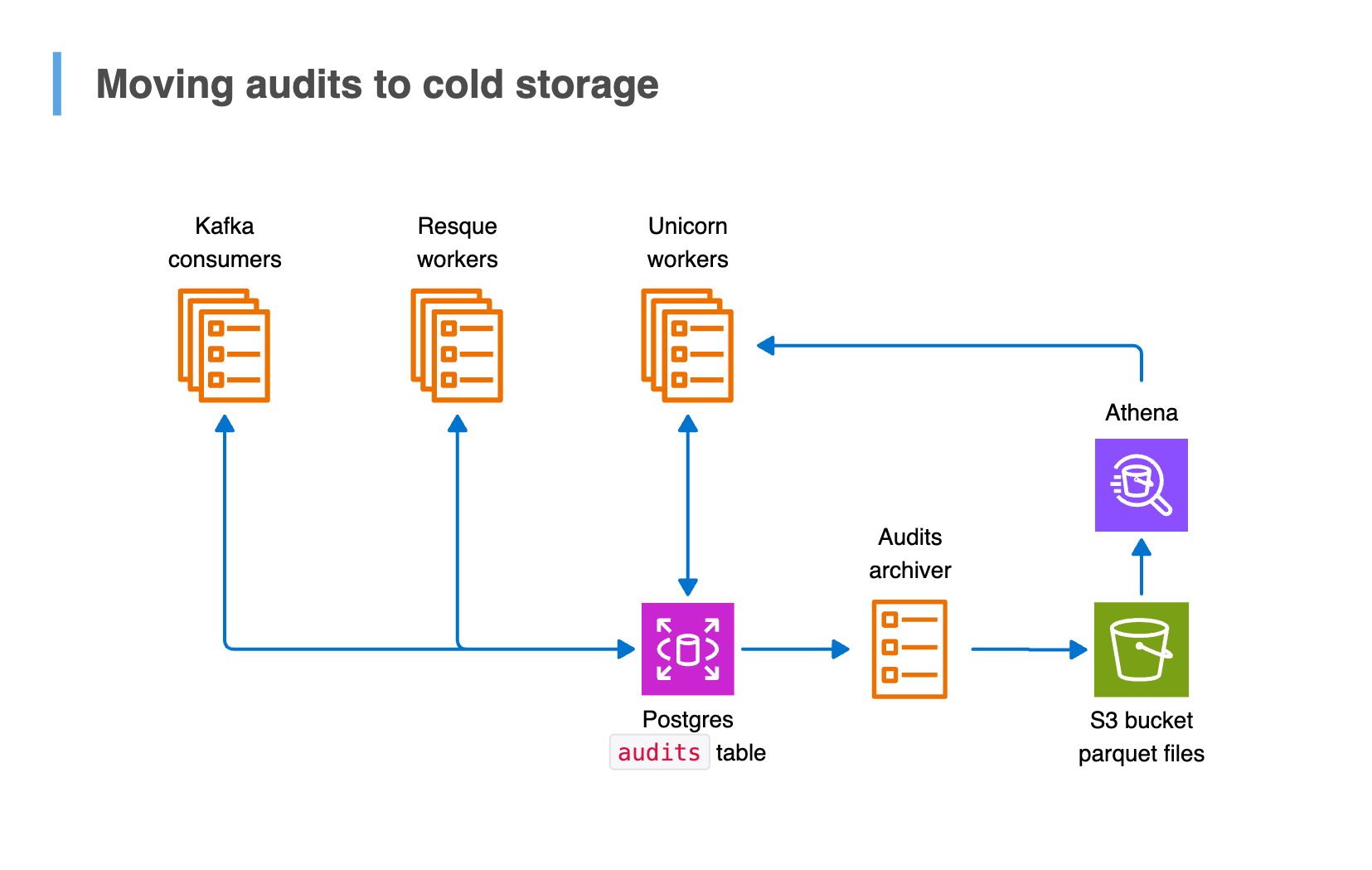
Cleaning up archived data efficiently
Extracting billions of historical audits to S3 was only step one. To keep the table size manageable, we archive older audit data continuously, ensuring long-term retention at lower storage costs. Once safely archived, we need to remove those rows from Postgres to prevent the table from growing indefinitely. However, dropping tens of millions of rows each month comes with its own performance pitfalls:
- MVCC overhead: Postgres' Multiversion Concurrency Control (MVCC) doesn't immediately remove deleted rows. Instead, it marks them as dead tuples, adding overhead to queries until
VACUUMreclaims the space. - Lock contention: Large deletes can lock indexes, slowing down concurrent writes. (Row-level locks weren't a concern for us since old audit data never changes.)
- Increased disk I/O and bloat: Frequent deletes fragment the table, inflating disk usage and degrading query performance over time.
Declarative partitioning to the rescue
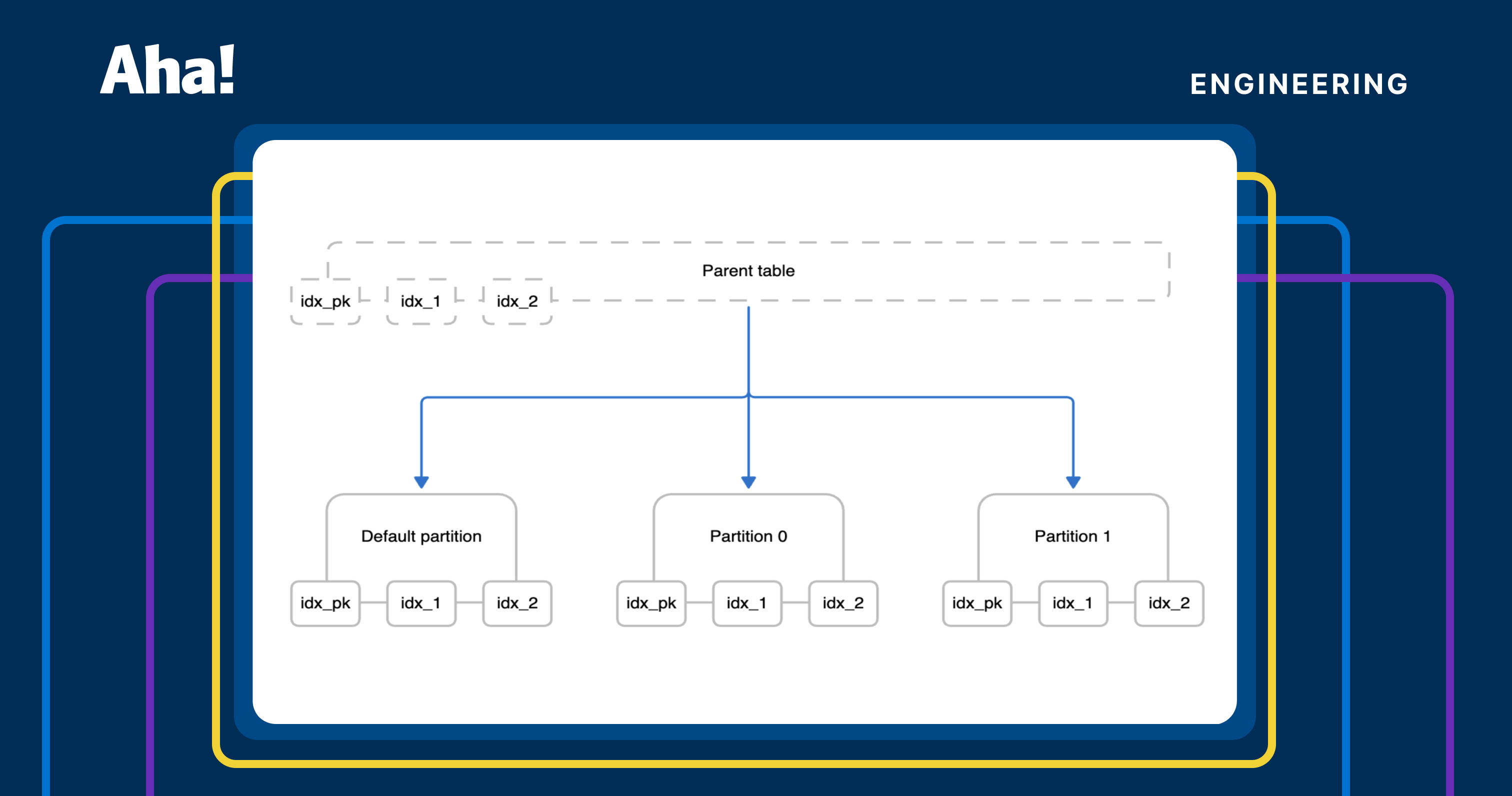
What is declarative partitioning?
When a table grows too large to manage efficiently, partitioning helps by splitting it into smaller, more manageable pieces. From the application's perspective, it still behaves like a single logical table. But it's divided into multiple physical partitions behind the scenes. Each partition stores a subset of the data and has its own indexes (which are virtually linked to the parent).
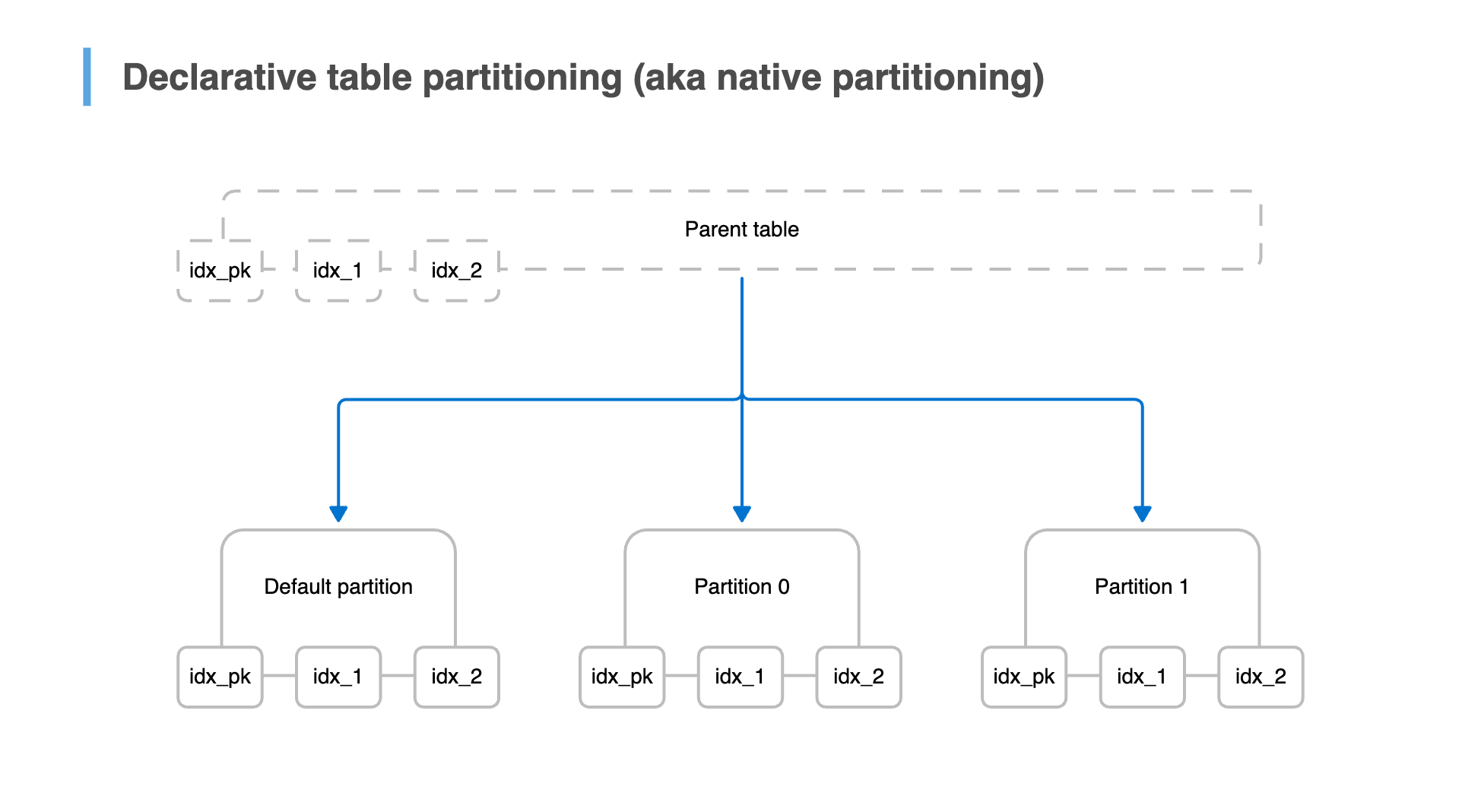
Postgres supports three built-in partitioning strategies:
- Range partitioning: Best when data is naturally ordered (e.g., time stamps, IDs). Rows are stored in partitions based on non-overlapping value ranges for a partition key.
- List partitioning: Useful when the partition key is an enum where values fall into discrete categories (e.g., country codes). Each partition contains rows matching an explicitly defined list of partition key values.
- Hash partitioning: Helps distribute data evenly when no natural range exists. Rows are assigned to partitions based on the result of applying a hash function on the partition key.
Range partitioning was the natural choice for our use case since we needed to separate audit records over time.
How does declarative partitioning help?
Partitioning a large table provides several performance and operational benefits:
- Faster queries with partition pruning: When a query includes a
WHEREclause filtering on the partition key, Postgres automatically skips irrelevant partitions. Partition pruning reduces the amount of data scanned and increases the likelihood that the most heavily used parts of indexes fit in memory. - Detaching a partition is fast: Deleting millions of rows is slow and painful, but detaching a partition is a near-instant metadata operation. Once detached, the partition is removed from query plans immediately, making it easy to drop old data that has been archived.
- Reduced MVCC and index maintenance overhead: Instead of performing costly
DELETEoperations, we can drop entire partitions. This avoids bloat,VACUUMoverhead, and excessive index maintenance.
For our use case, partitioning would enable us to manage table growth, improve query performance, and make archiving a low-impact operation. But we needed the right table design to make it work.
Designing a partitioned table
Choosing the right partition key is crucial — it determines how data is distributed across partitions.
If the table has a primary key, it must include the columns of the partition key (because Postgres enforces constraints and indexes at the partition level, not on the logical parent table). Therefore, the partitioning structure itself must prevent duplicates across partitions.
We wanted to partition the audits table chronologically, but our existing primary key was the id bigint column, not the created_at time stamp column. Our id values are tightly correlated with created_at because we use custom ID generation logic that encodes a time stamp component into each id. This lets us approximate a record's creation time from its id and vice versa — a property that makes partitioning by the id column a viable stand-in for partitioning by created_at.
(Yes, it's a 64-bit time-sortable ID. And no, we didn't use Snowflake.)
We decided to structure our partitioned audits table as follows:
- Each partition holds one month of data based on a range of
idvalues. - We keep 12 months of audit data in Postgres at any given time.
- Almost all writes occur in the "hot" partition (the most recent monthly partition).
- Most reads target the last one to two partitions. Whenever possible, queries are scoped by
idto leverage partition pruning. - Partitions older than 12 months are detached and archived in cold storage (S3).
This design gave us a solid plan for handling new data. But our audits table already held billions of records. How could we migrate them to partitions without bringing down the system?
Considerations for partitioning an existing table
Move vs. copy
We started with a monolithic audits table holding over a decade of history — or roughly 50% of the database's disk usage. We had several options, including:
- Moving rows from the old table to partitions: But this suffers from the same performance issues as bulk deletes. Each moved row must be deleted from the old table and reinserted into a partition, creating dead tuples that slow queries until the next
VACUUMreclaims space. Meanwhile, large batch inserts can contend for locks and cause replication lag. - Copying rows into a new partitioned table: But that would require increasing our RDS storage, which is expensive and challenging to reduce later.
During our initial investigation, we looked at pgslice, a popular partitioning tool for Rails applications. But pgslice copies data into new partitions, meaning we'd need twice as much storage during the migration. That wasn't an option for us.
Attaching a partition: The no-move solution
Instead of moving or copying data, we introduced partitioning without touching existing rows.
Postgres allows attaching an existing table as a partition, provided the column schemas are compatible. We could first create a new partitioned table structure:
CREATE TABLE partitioned_audits (LIKE audits INCLUDING ALL)
PARTITION BY RANGE (id);Then, attach the existing table as a partition:
ALTER TABLE ONLY partitioned_audits ATTACH PARTITION audits
FOR VALUES FROM ('0'::bigint) TO ('7410357159843594240'::bigint);Finally, rename the tables:
ALTER TABLE audits RENAME TO audits_p0;
ALTER TABLE partitioned_audits RENAME TO audits;The result? The application seamlessly switches to using the partitioned table with zero downtime.
Of course, there's a catch. For declarative partitioning to work, Postgres enforces strict rules:
- Partition ranges must not overlap.
- Every row must belong to the correct partition.
- Postgres automatically routes inserted tuples to the right partition.
But here's the problem: Before Postgres lets you attach an existing table full of data, it must verify that every row fits within the range for the partition key. And how does it do that? A full table scan.
One does not simply avoid a full table scan
By default, attaching a partition triggers a sequential scan of the entire table (after acquiring an ACCESS EXCLUSIVE lock, which blocks all concurrent reads and writes). Given our table size, we estimated this could take hours — which was unacceptable.
Fortunately, there's a trick to skip the full scan: Postgres will trust a valid CHECK constraint if it matches the partition range.
Sounds perfect. Except …
Creating a valid CHECK constraint requires a full table scan with an ACCESS EXCLUSIVE lock.
The solution? Before attaching the existing table as a partition, you could create the CHECK constraint as NOT VALID:
ALTER TABLE audits ADD CONSTRAINT audits_p0_id_check
CHECK (id >= '0'::bigint AND id < '7410357159843594240'::bigint) NOT VALID;A NOT VALID constraint immediately applies to new inserts and updates, but Postgres won't trust that existing rows comply. That's where validation comes in.
As a separate step, you can validate the constraint with:
ALTER TABLE audits VALIDATE CONSTRAINT audits_p0_id_check;Validating the constraint requires a full table scan (there's no avoiding it entirely), but it uses a SHARE UPDATE EXCLUSIVE lock, which allows concurrent reads and writes. Since Postgres knows no invalid data can be inserted during validation, it doesn't need a more restrictive lock. Once the constraint is validated, we can attach the table as a partition without downtime.
With our CHECK constraint strategy, we were almost ready to validate and attach the existing audits table as a partition.
Just when we thought we had it solved, we hit one final obstacle.
Dealing with out-of-range data
The ghosts of IDs past (and future)
Our audits table contained some rows with id values way outside the expected range. These were the result of a long-fixed issue involving user-supplied time stamps far in the future. Since our ID generator is time-based, those records ended up with IDs that didn't line up with the rest of the dataset. The data itself was valid and needed to be preserved, but the outlier IDs fell outside the partition range we planned to enforce.
As a side note: If you're designing a new table schema, it's worth seriously considering a primary key that uses time-sortable 128-bit UUIDs generated in Postgres, rather than hand-rolling your own ID generation logic in the application. It could save you a lot of pain later on.
Fortunately, Postgres supports a default partition, which acts as a catch-all for rows that don't fit into any other partition. Before validating the CHECK constraint, we needed a way to move out-of-range rows into the default partition without downtime. That's where inheritance came in.
An intermediate solution: Partitioning using inheritance
Before Postgres 10 introduced declarative partitioning, partitioning was handled using table inheritance. This feature is still supported today.
- Child tables inherit from a parent table with a compatible column schema.
- Queries against the parent table include results from all child tables.
- Postgres does not enforce any partitioning strategy; it simply executes the query against all child tables and appends the results.
With partitioning using inheritance, Postgres does not automatically route new rows to the correct partition. To handle this, a BEFORE INSERT trigger on the parent table ensures new rows go into the correct partition.
Unlike declarative partitioning, table inheritance imposes no restrictions on partition boundaries and no costly full table scans when attaching partitions.
Trade-offs of partitioning using inheritance
While this approach helped us bridge the gap, it wasn't a viable long-term solution. Some key drawbacks included:
- Trigger maintenance: We must update the trigger logic whenever we add or remove a partition.
- No partition pruning: Queries against the parent table hit every child partition, even when most are irrelevant.
- Performance limits: Query planning slows as the number of partitions increases, and the
BEFORE INSERTtrigger is significantly slower than declarative partitioning's built-in tuple routing.
Partition pruning is essential for our use case, and we wanted a scalable long-term solution without the ongoing maintenance burden of trigger updates. We are also concerned about the performance of inserts.
As a permanent solution? No way. But as a stepping stone to declarative partitioning? Table inheritance with a trigger was just what we needed.
A staged rollout plan
Phase 0: Setting up partitioning support in Rails
Rails 7.1 didn't directly support Postgres partitioning, so we used pg_party for migration helpers and Active Record model methods. We also added some custom plumbing code to make the process easier. In Rails 8.0, native support for table inheritance and declarative partitioning began appearing in Active Record (though it remains undocumented).
To simplify partition management, we implemented convenience methods to abstract the SQL for:
- Querying existing partition boundaries
- Inheriting and detaching inherited tables
- Managing extended statistics, including column-level statistics targets
- Ensuring row-level security (RLS) policies are consistently applied across partitions
To make custom schema methods available in database migrations and on ActiveRecord::Base.connection, you can include them in the Postgres connection adapter using a Rails initializer:
ActiveSupport.on_load(:active_record) do
ActiveRecord::ConnectionAdapters::PostgreSQLAdapter.include CustomSchemaHelpers
endPhase 1: Setting up partitioning using table inheritance
Before switching to declarative partitioning, we first needed to introduce table inheritance. This initial structure allowed us to segment new data into partitions and handle out-of-range rows while ensuring the application continued querying a single logical table.
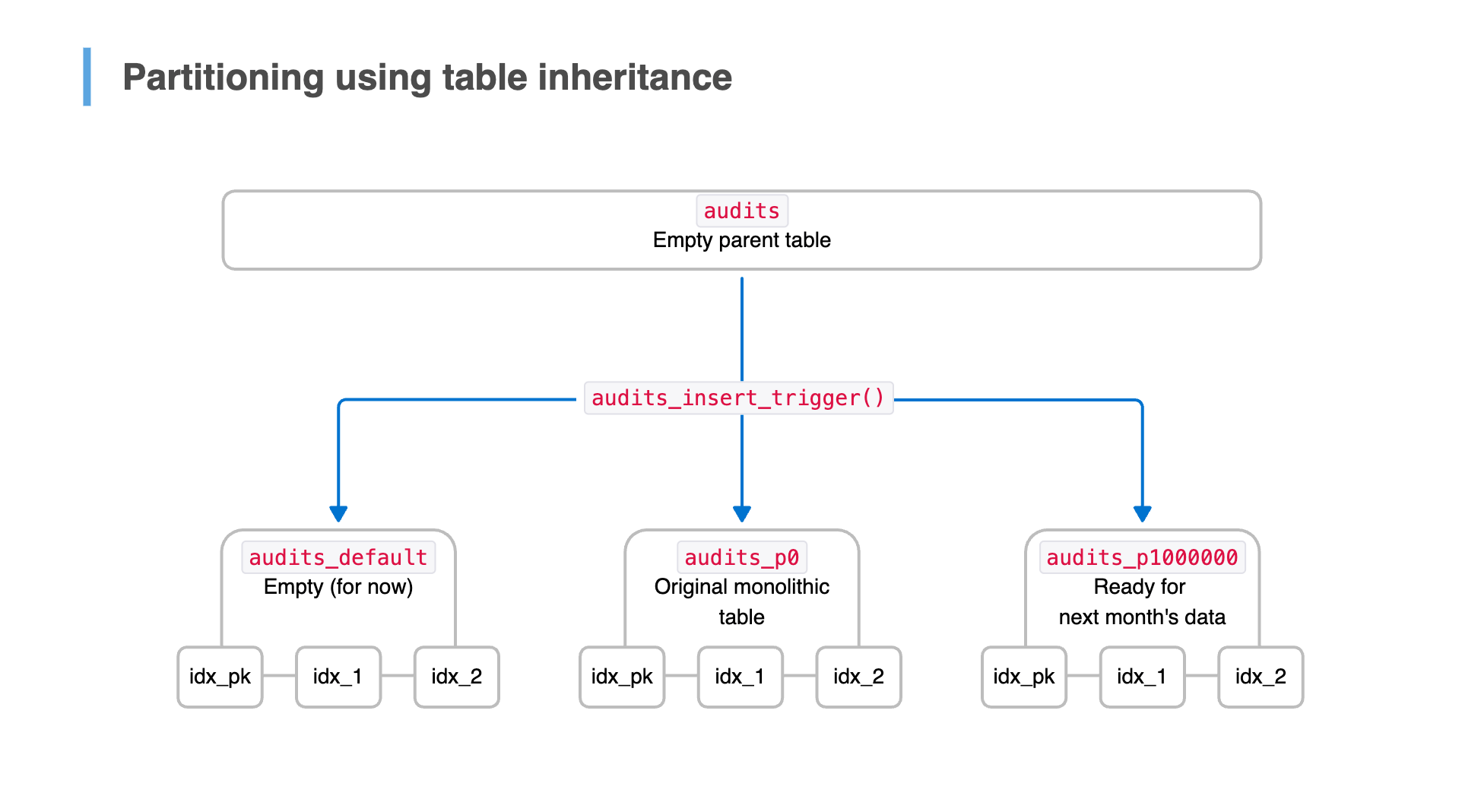
The migration plan
Our approach:
- Create a parent table (
partitioned_audits) with the same column schema as the existingauditstable. - Create a default partition to catch any out-of-range rows.
- Create a child table for the next month's data, inheriting from the parent table and adding a
CHECKconstraint to enforce itsidrange. - Define a
BEFORE INSERTtrigger to route new rows into the correct partition. - Set the existing
auditstable to inherit frompartitioned_auditsso historical data remains accessible. - In a single transaction, rename tables:
- Rename
auditstoaudits_p0(designating it as the first partition). - Rename
partitioned_auditstoaudits, so the application continues querying the new parent table without modification.
- Rename
After this, the application continued interacting seamlessly with audits — no code changes required.
Routing new rows with a trigger
By default, inserts go into the parent table, so we added a BEFORE INSERT trigger on the parent table to redirect new data to the appropriate child table.
For example, you could define a trigger function like this:
CREATE OR REPLACE FUNCTION audits_insert_trigger()
RETURNS TRIGGER AS $$
BEGIN
IF (NEW.id >= 0 AND NEW.id < 1000000) THEN
INSERT INTO audits_p0 VALUES (NEW.*);
ELSIF (NEW.id >= 1000000 AND NEW.id < 2000000) THEN
INSERT INTO audits_p1000000 VALUES (NEW.*);
ELSE
INSERT INTO audits_default VALUES (NEW.*);
END IF;
RETURN NULL;
END;
$$ LANGUAGE plpgsql;The application can continue inserting into audits as usual, while the trigger automatically routes each row to the correct partition.
Handling constraints, indexes, and RLS
When using table inheritance, some database objects behave differently than in a regular table:
NOT NULLconstraints: Defined on the parent table and inherited by all child tables- Indexes, primary key, and
UNIQUEconstraints: These must be defined separately on each child table; they are not connected to the parent. - Extended statistics: Must be configured per partition, if needed
- Row-level security (RLS) enforcement: Postgres applies only the RLS policy of the table explicitly targeted by the query.
If a query targets the parent table (audits), Postgres applies only the parent's RLS policy — even though the results include data from inherited tables. To future-proof against direct queries to child tables, define RLS policies on every partition as a best practice.
Phase 2: Validating partition boundaries
With table inheritance and a trigger in place, new audit records were correctly routed to their respective partitions. However, our existing audits_p0 partition still contained years of historical data that had never been checked against partitioning rules. Before transitioning to declarative partitioning, we needed to ensure every row in audits_p0 conformed to the expected id range.
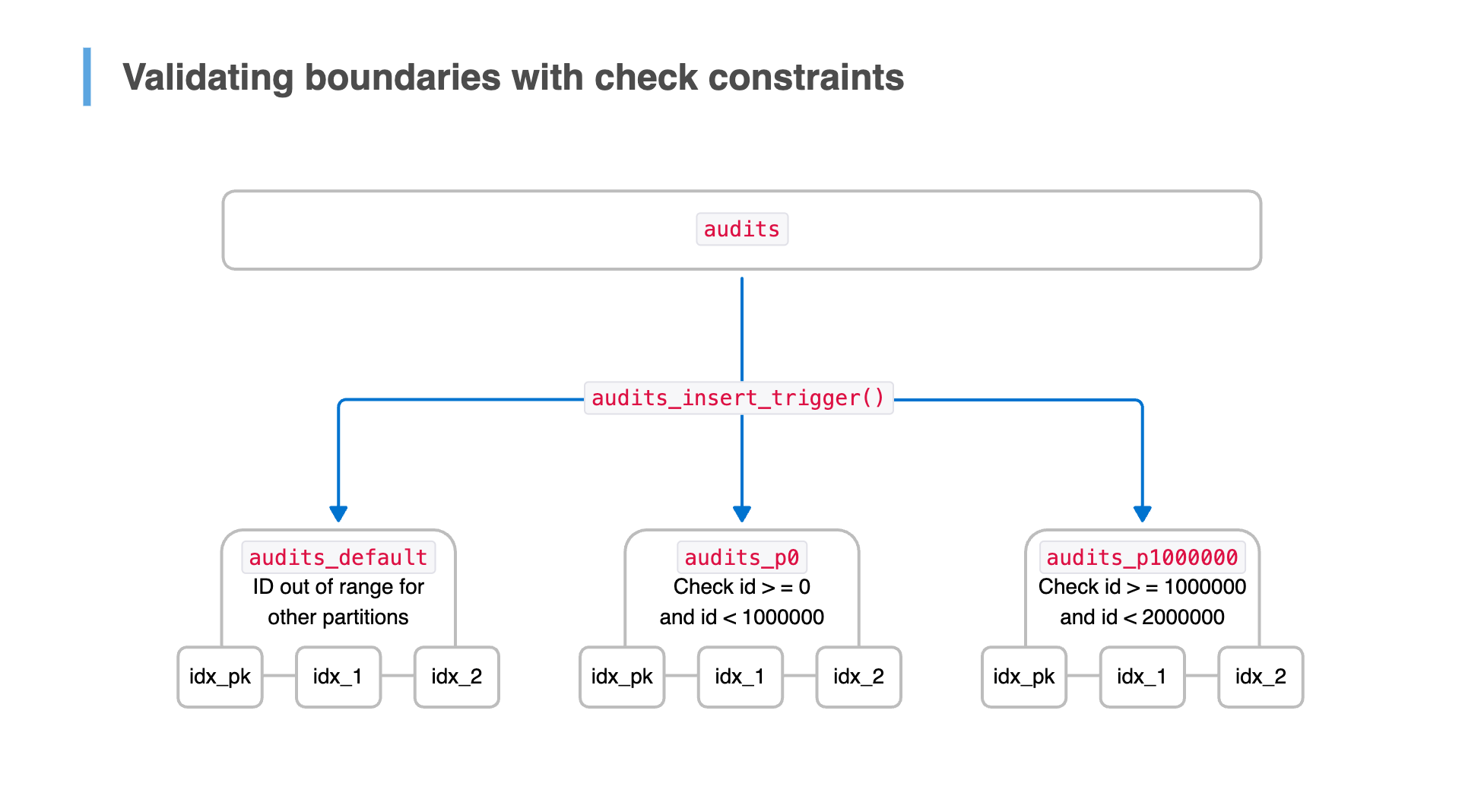
Ensuring partition integrity
To enforce partition boundaries without downtime, we took the following approach:
- Add a
CHECKconstraint onaudits_p0to define theidrange for the partition. We initially marked it asNOT VALIDto avoid locking the table, meaning it would apply only to new inserts. - Move out-of-range rows to the default partition for later review; some historical records had
idvalues that didn't align with our partitioning rules. - Validate the
CHECKconstraint to ensure every remaining row inaudits_p0fits within the expected range. Validation does not block concurrent queries since the constraint is already enforced for new writes.
As expected, validating the constraint was time-consuming, taking several hours to scan billions of rows.
Cleaning up out-of-range data
After validation, we examined the records in the default partition. Some had been assigned incorrect id values due to past application issues. Others had been inserted when partitioning rules weren't correctly enforced due to a problem with our trigger function. We corrected IDs where required and moved valid records back into audits_p0.
Once this cleanup was complete, the default partition was empty, ensuring out-of-range rows would be immediately visible for investigation in the future. We set up monitoring to track the default partition's row count as a custom Amazon CloudWatch metric. If new rows appear, an alarm notifies us so we can address issues before they become a bigger problem.
Phase 3: Switching to declarative partitioning
With all partition CHECK constraints validated and historical data cleaned up, we were ready to migrate to declarative partitioning. This ultimate solution would eliminate the need for a routing trigger and allow Postgres to optimize query execution with partition pruning.
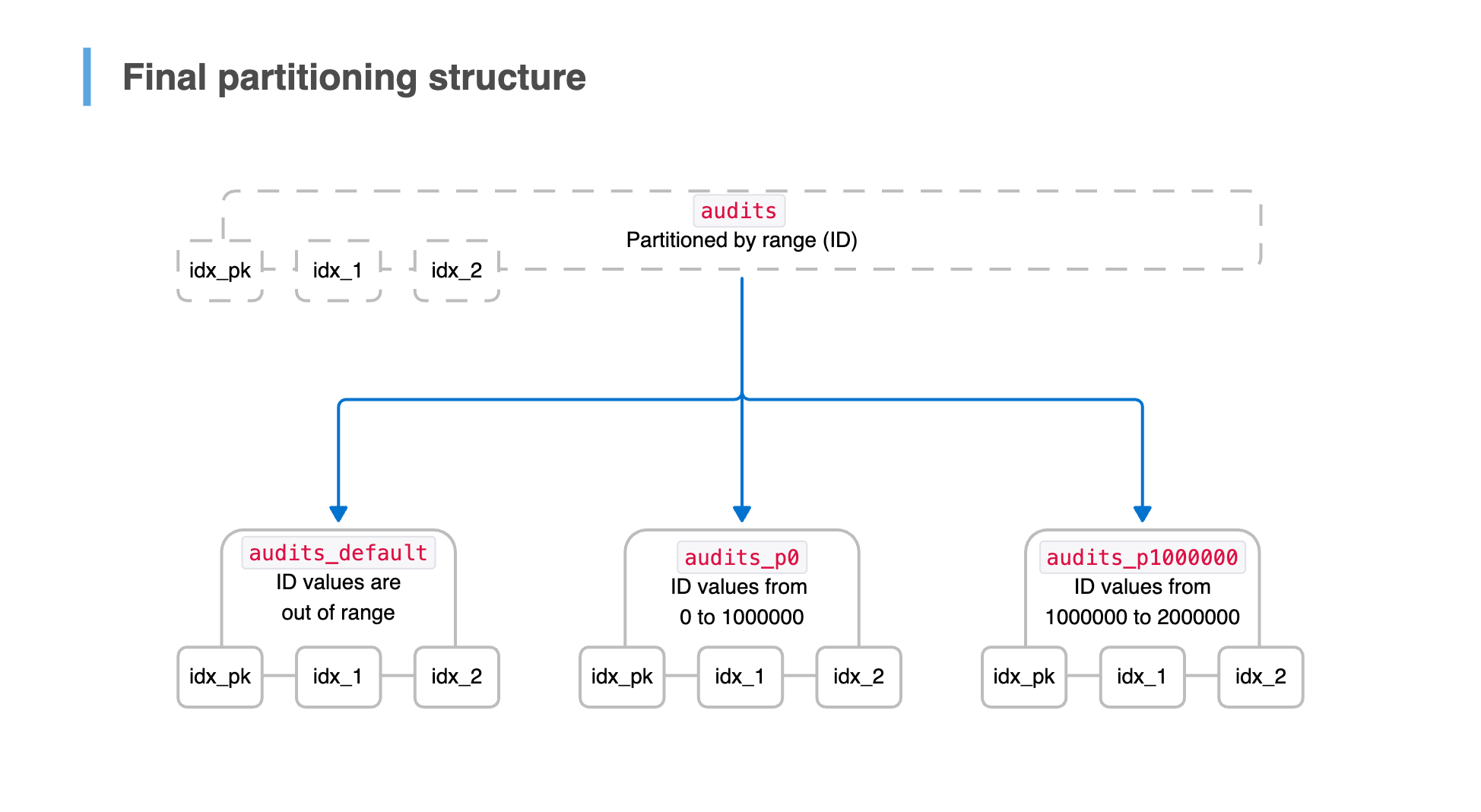
The migration plan
We first created a new partitioned version of the audits table, explicitly declaring it to be partitioned by range on the id column. It mirrored the existing audits table's column schema, indexes, constraints, and RLS policies, ensuring a seamless transition.
To complete the migration without downtime, we executed the following metadata-only operations in a single transaction:
- Detach inherited partitions by running
ALTER TABLE … NO INHERITon each child table. - Attach each partition to the new parent with an
idrange matching its validatedCHECKconstraint. - Seamlessly swap the parent table:
- Rename
auditstoold_audits, preventing queries from targeting the old structure. - Rename the new partitioned table to
audits, keeping application logic unchanged.
- Rename
Finally, we dropped the old table and removed the trigger function, as declarative partitioning now handled tuple routing automatically.
Handling indexes when attaching a partition
Unlike table inheritance, declarative partitioning centralizes index management at the parent level, but indexes remain physically stored at the partition level.
When attaching an existing table as a partition, for each regular (non-primary key/unique) index defined on the parent table, Postgres performs the following steps:
- Check if the child table has an index that conforms to the parent index's definition.
- If no matching index exists, Postgres automatically creates one, requiring an
ACCESS EXCLUSIVElock that blocks reads and writes on the partition. - Attach the child index, logically linking it to the parent index to provide a unified view to the query planner and prevent the child index from being removed independently.
When a partition contains billions of rows, the automatic index creation can cause prolonged downtime due to lock contention. To avoid this, manually create indexes CONCURRENTLY on the child table before attachment, ensuring they match the parent table's indexes. Then, Postgres can attach them instantly as a metadata-only change.
Handling constraints when attaching a partition
Under declarative partitioning, constraints are defined at the parent table level but enforced locally on each partition.
For INSERT and UPDATE operations, Postgres first routes each tuple to the correct partition and then applies constraints at the partition level. Thus, primary key and UNIQUE constraints must include the partition key to ensure any potentially conflicting rows are directed to the same partition where the constraint is enforced correctly.
When attaching an existing table as a partition, Postgres verifies constraints as follows:
NOT NULLand foreign key constraints must already exist on the child table. If they are missing, Postgres rejects the attachment.CHECKconstraints declared on the parent table are inherited by partitions. If the child table lacks a matching constraint, Postgres automatically injects one, requiring anACCESS EXCLUSIVElock that blocks reads and writes while the table is scanned.- Primary key and
UNIQUEconstraints are enforced via indexes. Postgres attempts to attach the child table's corresponding index to the parent index. If no matching index exists, the partition attachment is rejected.
All necessary constraints should be pre-defined on the child table before attaching it as a partition to ensure a fast, metadata-only operation.
Partition maintenance: Automating creation and cleanup
Encapsulating partition logic in model methods
The audits table was our first to be partitioned by id. But as our database scales, it won't be the last.
To simplify maintenance, you can implement a reusable concern to enable partition-aware queries and lifecycle management:
module PartitionableById
extend ActiveSupport::Concern
included do
range_partition_by :id # Provided by pg_party
# Ensures queries filtering by timestamp leverage partition pruning
scope :in_created_at_range, -> (created_at_range) do
# Convert timestamps to an estimated id range based on our ID generator
# …
where(created_at: created_at_range, id: id_range)
end
end
class_methods do
def create_next_partition!
# Determine the next partition name and range
# …
# The create_partition method (pg_party) handles most partition setup
create_partition(name: partition_name, start_range: min_id, end_range: max_id)
# Additional setup for database objects pg_party does NOT manage:
# - RLS policies
# - Column-level statistics targets
# - CHECK constraints
# …
end
def detach_oldest_partition!
# Identify and detach the oldest partition
# …
end
def detached_partitions
# Return a list of detached partitions
# …
end
end
endTo leverage partition pruning, any queries that filter by the created_at column should use the in_created_at_range Active Record scope instead.
Automating partition management
To keep the database manageable, we run scheduled jobs in Rails to automate partition maintenance activities:
- Creating new partitions ahead of time to ensure seamless inserts
- Detaching old partitions after audit data is archived and reconciled
- Dropping detached partitions to free up disk space once they are no longer needed
Partition rotation is fully automated, reducing operational overhead while ensuring storage remains efficient and queries stay fast.
Why we didn't use pg_partman (yet)
We considered using pg_partman with pg_cron for automated partitioning inside Postgres. However, pg_partman's monitoring tools rely on pg_jobmon for job monitoring, which isn't available on Amazon RDS.
Rather than adopting a black-box approach, we built a Rails-based solution that integrates with our existing observability stack:
- Sentry captures errors in partition maintenance jobs.
- Datadog monitors performance metrics for partition operations.
- Amazon CloudWatch tracks the size of the default partition and alerts us if unexpected rows are inserted.
This setup gives us complete control and visibility, allowing us to detect and resolve issues early. We also followed pg_partman's table naming conventions, making it easy to switch later if we change our minds.
Wrapping up
Partitioning our audits table was a significant investment, but it paid off in performance and scalability. The staged rollout allowed us to migrate billions of rows without downtime, and automated partition maintenance keeps everything running smoothly.
Partitioning might be your best path forward if you're dealing with a massive Postgres table — but success comes down to getting the details right. Choose your partition key carefully, plan for the migration challenges, and automate partition management.
Inspired by this approach? We're happy and hiring engineers — join us.